VisionMealRL
An end-to-end meal-planning class project that connects visual nutrition estimation with a DQN planner, recommending meals and portions across multi-day horizons while balancing nutrition goals, user preference, and diversity.
Overview
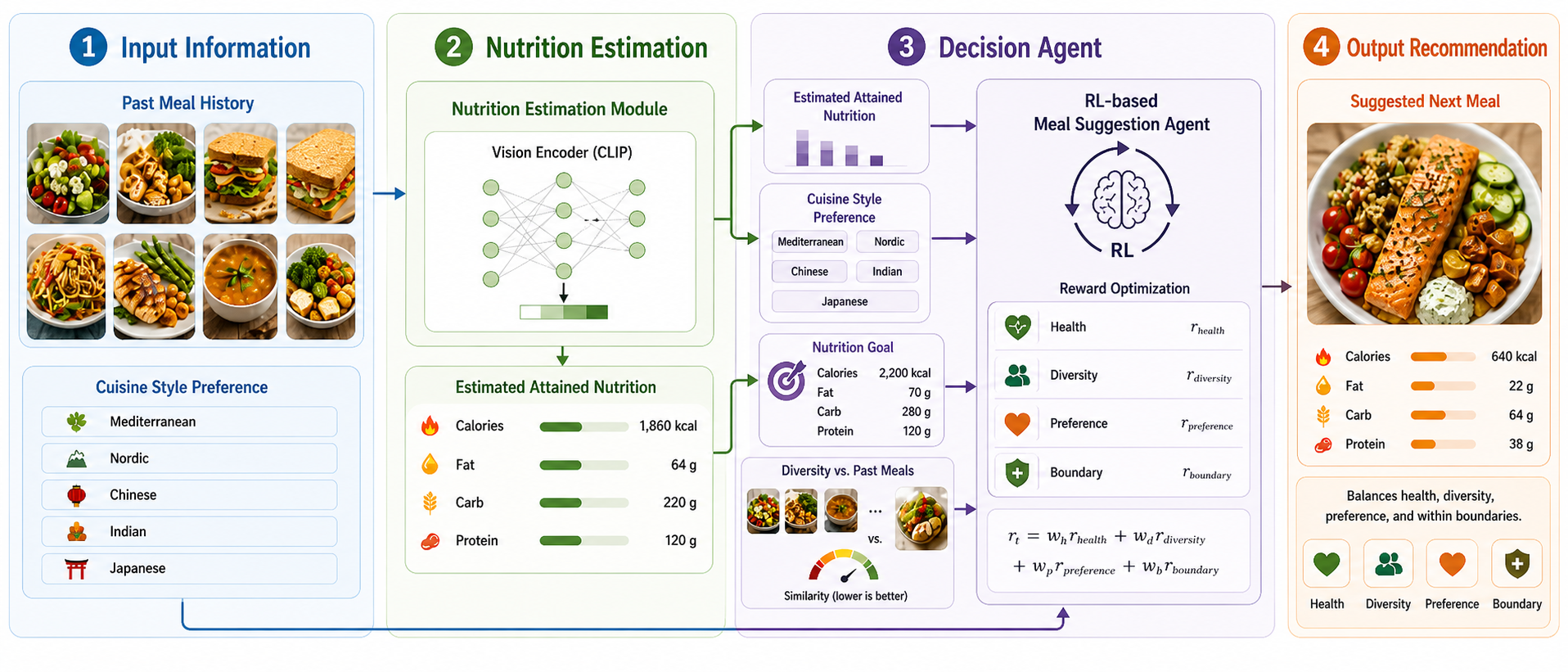
VisionMealRL began with a practical friction point: nutrition apps ask users to log too much manually. We explored an end-to-end pipeline where a user could capture meal images, use computer vision to estimate nutrition and ingredient signals, and feed those signals into a reinforcement-learning planner that recommends future meals.
The maintained demo focuses on the planning side. It uses a DQN meal-planning agent to recommend meal templates and portion sizes across 1, 3, 7, and 21-day horizons while balancing nutrition deficit closure, preference alignment, dietary diversity, and meal-slot validity.
My role
I focused on the RL agent: implementing the meal-planning environment, training and evaluating the action-scoring DQN, running horizon experiments, analyzing the agent against greedy baselines.
The team project also included a computer vision module for automated nutrition estimation and a recipe-catalog construction pipeline. Those pieces made the project more than a recommender: the broader goal was to reduce manual dietary logging and close the loop between observed meals and future planning.
Computer vision module
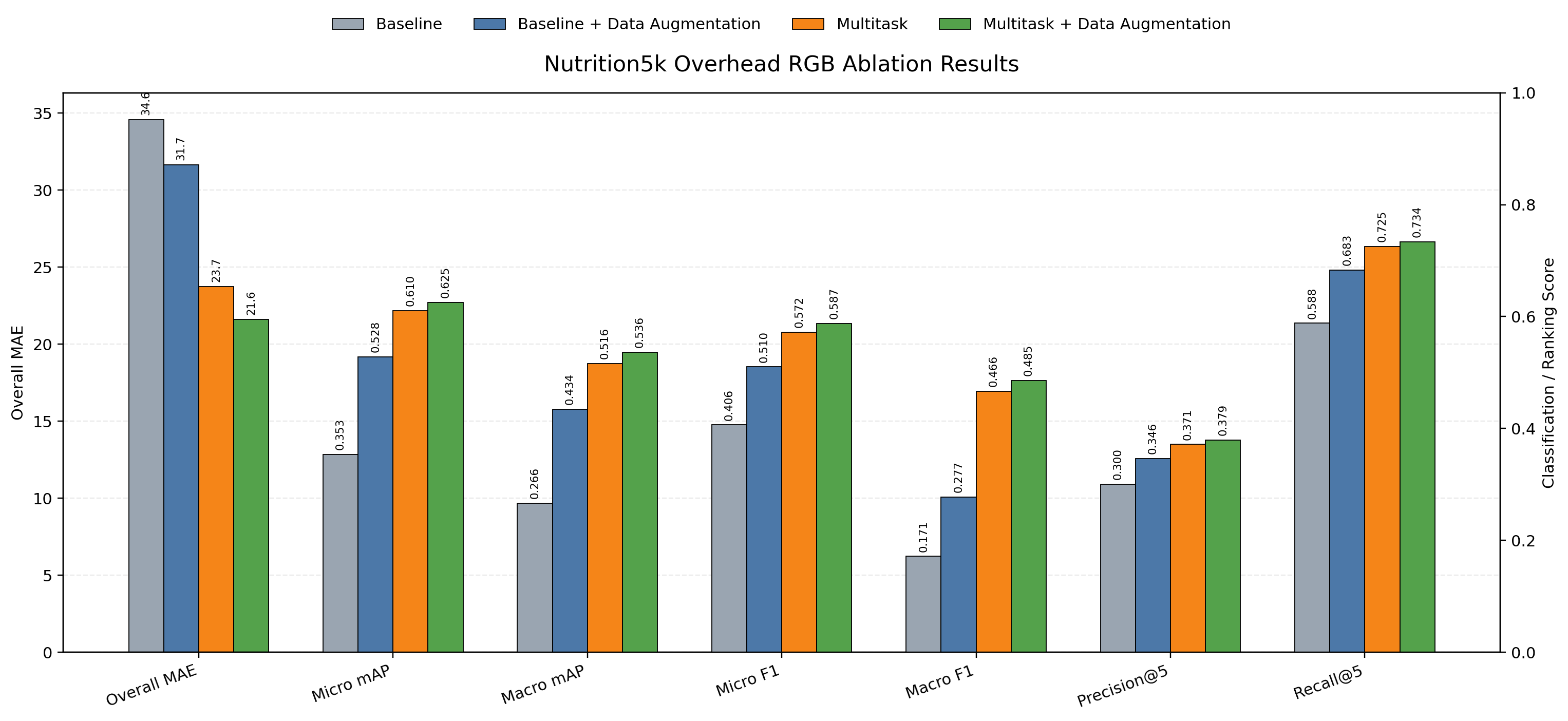
The perception module used OpenCLIP with a ViT-B/32 visual encoder on Nutrition5k meal images. For each dish, image embeddings were mean-pooled into a dish-level representation, then trained for two tasks:
- Nutrition regression for calories, mass, fat, carbohydrates, and protein.
- Multi-label ingredient classification over frequent visible ingredients.
The strongest setting used multitask fine-tuning with data augmentation. This was useful because the RL planner needs meal representations that are both nutritionally meaningful and semantically tied to ingredients.
Meal-planning agent
We formulated meal planning as a finite-horizon MDP. Each episode spans a user-selected number of days, with breakfast, lunch, and dinner decisions each day. At every step, the agent selects a meal template and portion multiplier from a catalog.
The state includes the user’s daily and episode-level nutrition deficit, nutrition target, remaining time, recent meal history, current meal slot, and preference representation. The action combines a meal representation with scaled nutrition, portion size, and slot-validity features.
The reward combines four terms:
- Nutrition progress: how much the action closes the remaining deficit.
- Preference alignment: similarity between the selected meal and the user’s preference profile.
- Dietary diversity: distance from recent meal history.
- Boundary adherence: daily and episode-level bonuses for ending near the target.
Action-scoring DQN
The action space contains thousands of meal-portion choices, so treating every action as an unrelated ID would waste structure. We used an action-scoring DQN: a state encoder maps the current planning state into a latent vector, while an action encoder maps each candidate meal-portion feature into the same space. The model scores state-action compatibility and shares learning across nutritionally or semantically similar meals.
This mattered most at longer horizons. Greedy baselines can optimize the next meal, but they do not reason about how breakfast affects lunch, dinner, and future days. The DQN learned a value function that accounted for downstream consequences.
Results
Against random, health-only greedy, and multi-objective greedy baselines, the DQN performed best on nutrition goal attainment and episodic deficit closure across planning horizons. In the report, the DQN reached 1.00 nutrition goal attainment at the 7-day horizon and 0.965 at the 21-day horizon, outperforming the myopic multi-objective baseline.
The main takeaway was not that RL is always necessary for meal recommendation. It was that learned temporal credit assignment becomes more useful when the task shifts from one-shot recommendation to multi-day planning.

What we learned
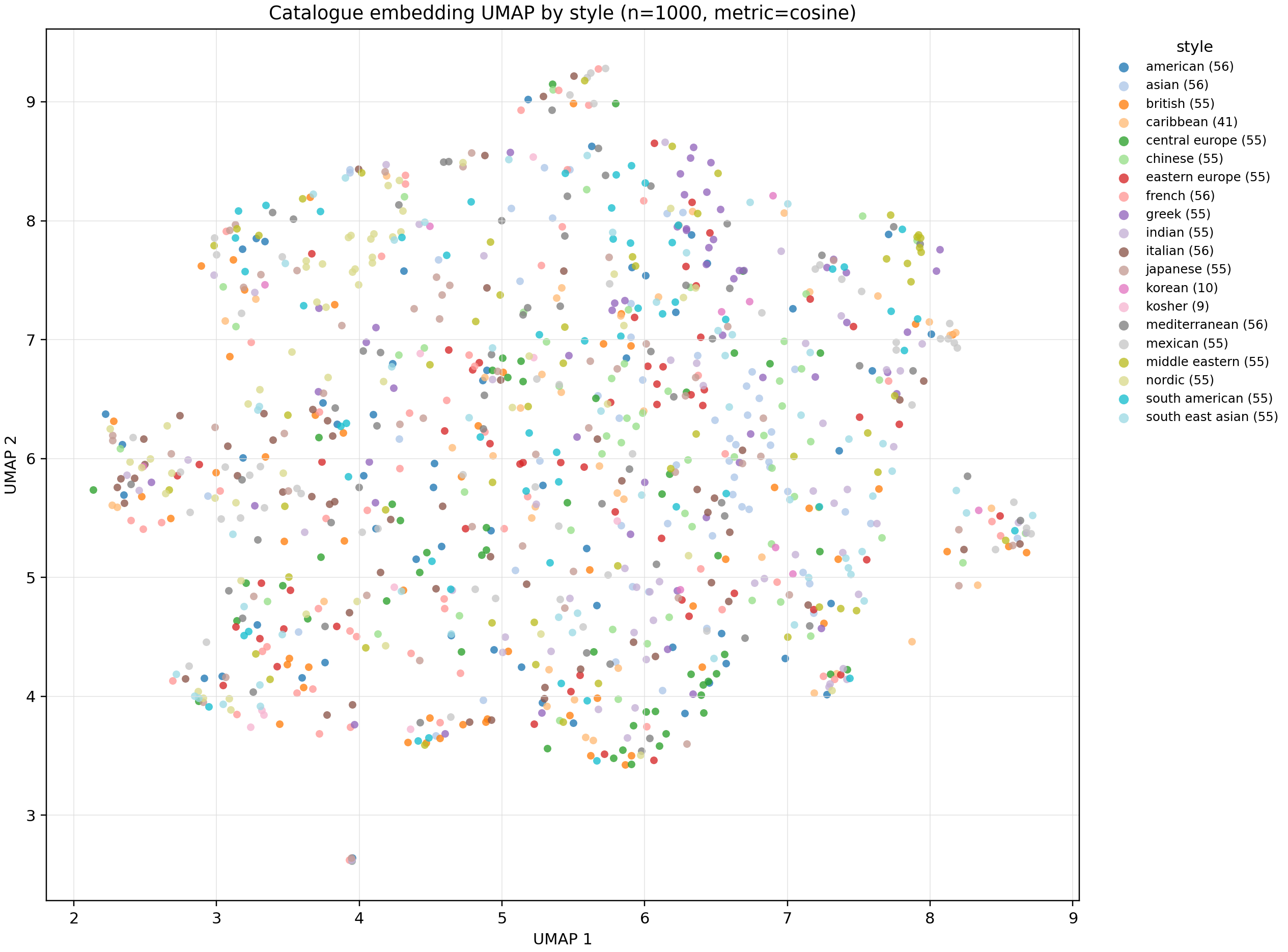
The project exposed a useful failure mode in the representation space. The UMAP visualization showed that CLIP image embeddings grouped meals more by visual appearance than by dietary style, so style-based preference embeddings did not reliably retrieve meals from the intended cuisine or preference family.
That result directly motivated the current redesign of the preference representation. Instead of relying on a single image embedding, we used a three-component meal representation: ingredient vectors, cuisine embeddings, and recipe-name embeddings. This gives the planner more explicit handles for taste, style, and semantic similarity, while keeping the RL environment compatible with user-selected example meals.
It also clarified why the CV part is hard. Single-view RGB images are limited for portion estimation, and natural recipe photos differ from the controlled overhead images in Nutrition5k. A more robust version would likely use video or multi-view capture to estimate food volume before passing nutrition estimates into the planner.