Taiwan Visual-Language Model 70B
Continual pre-training of ViT-L + Llama3-Taiwan-70B on 50M images and 3B text tokens grounded in Taiwanese culture.
Overview
We continually pre-trained a multimodal system grounded in Taiwanese culture using ViT-L as the vision encoder and Llama3-Taiwan-70B as the language backbone. The pre-training corpus included 50M image-text pairs and image-text-interleaved entries totaling 3B text tokens. The setup follows LLaVA-style architecture: image features from the vision encoder are projected and concatenated with language embeddings before being passed to the LLM.
My contribution
- Built and validated large-scale multimodal data for VLM pre-training, including image-text and interleaved image-text data.
- Supported the VLM pre-training workflow around ViT-L, Llama3-Taiwan-70B, Megatron-LM, NemoCurator, and DeepSpeed.
- Analyzed qualitative model outputs to identify instruction-following behavior and gaps for later visual instruction tuning.
Key finding
During development, we found that the model retained instruction-following behavior even without explicit visual instruction tuning. We attribute this to Llama3-Taiwan’s instruction-aligned language backbone: once visual features were projected into the language model’s embedding space, the model could often apply its existing instruction-following ability to image-conditioned inputs.
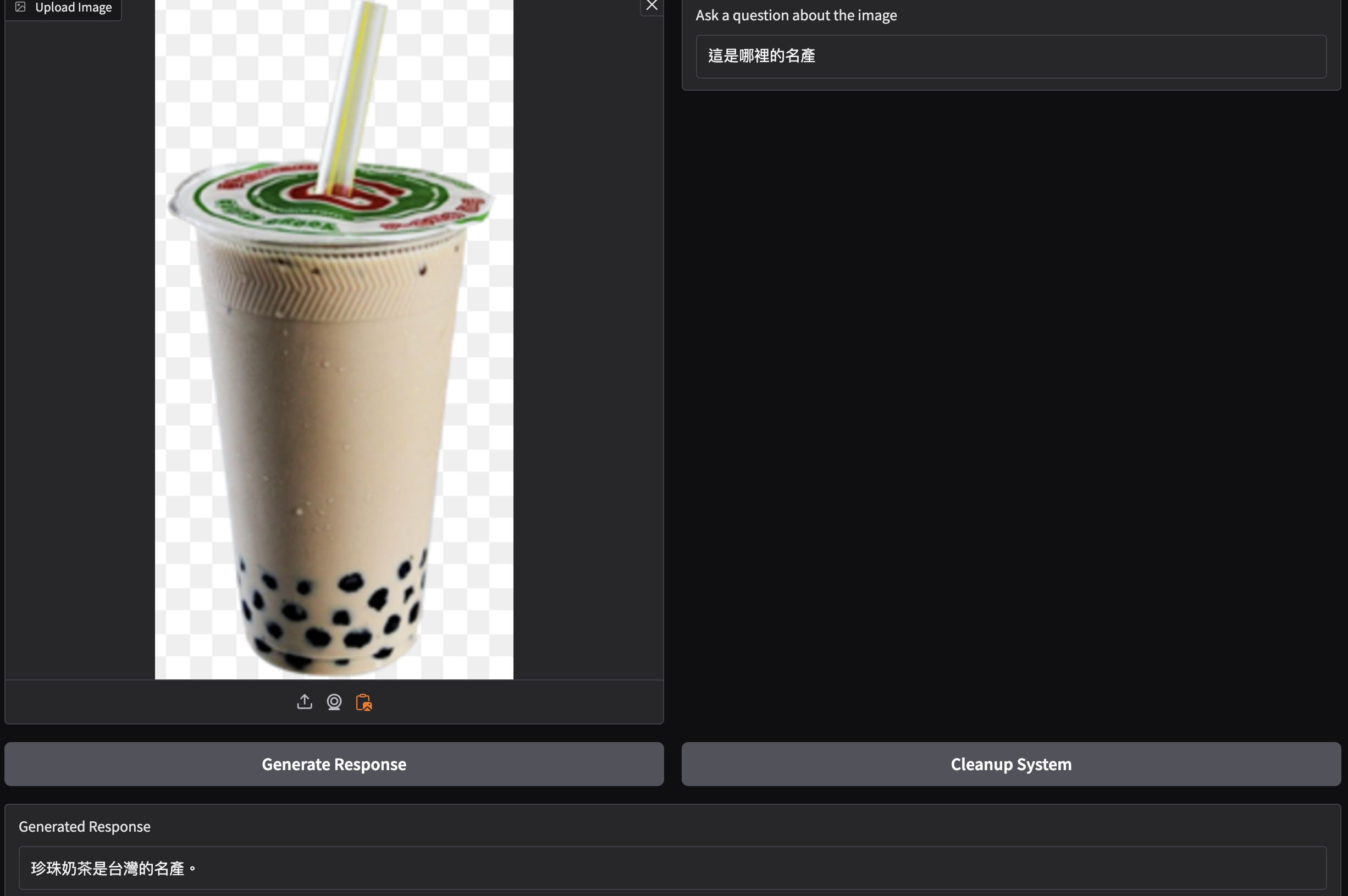
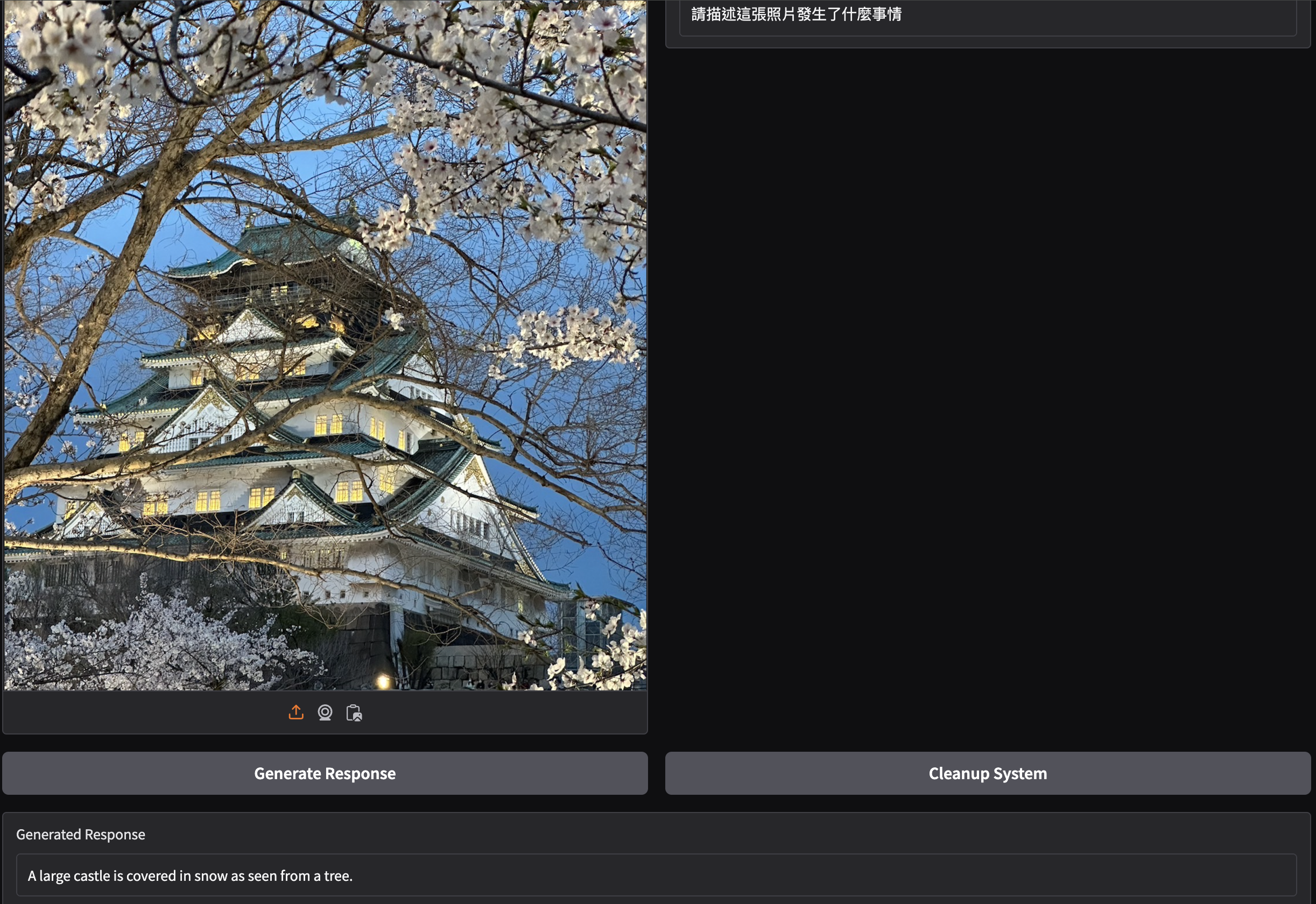
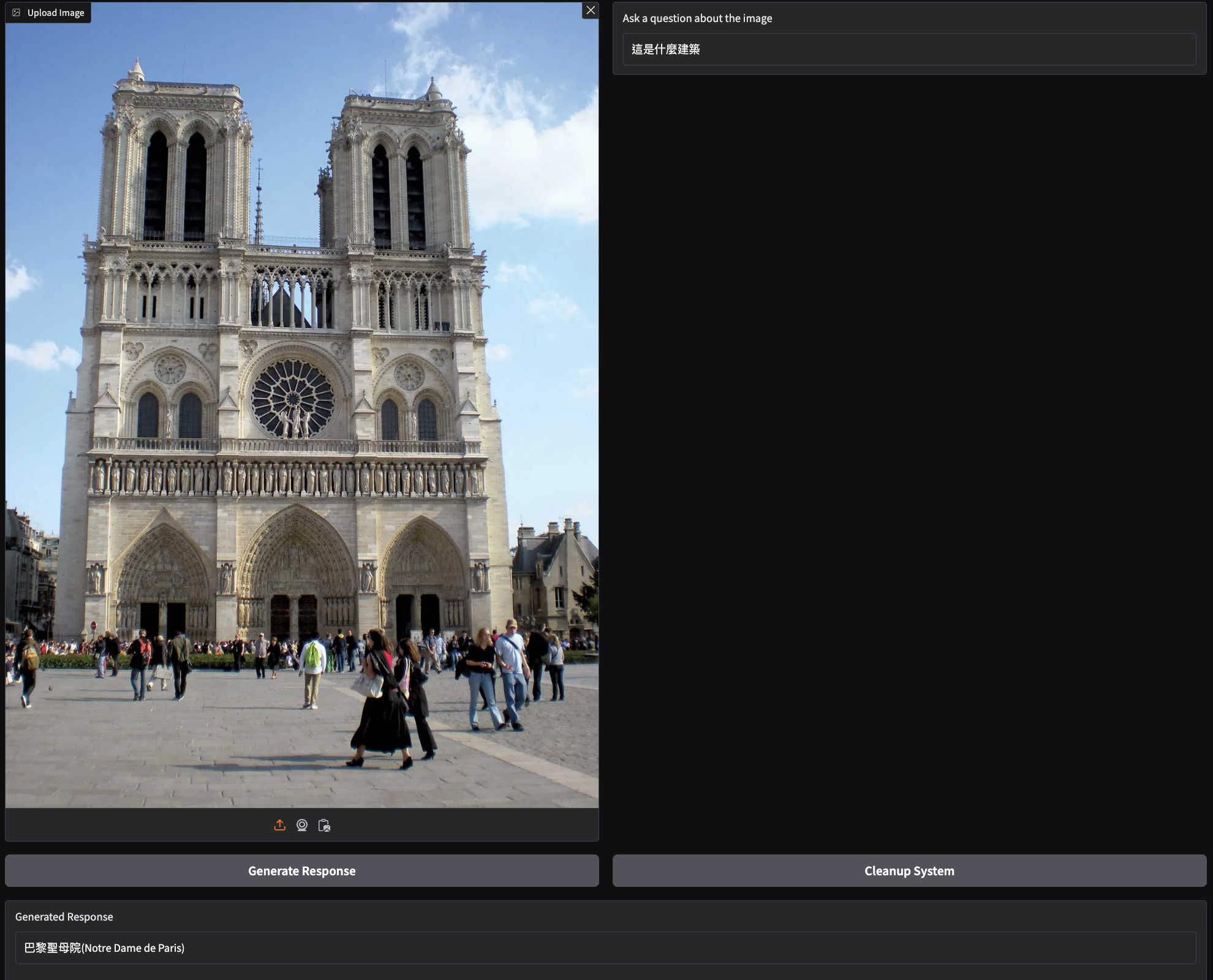
Demo conversations
The model can recognize objects, landmarks, and culturally specific food. Below are example outputs from image-conditioned conversations.

Current direction
Next steps include visual instruction tuning on Taiwan-specific QA and captioning data, along with more systematic evaluation across vision-language benchmarks and culturally grounded tasks.